

Table of Contents
Imagine if computers could think, understand language, and even have conversations just like humans. That’s exactly what Artificial Intelligence (AI) aims to achieve! AI is all about teaching machines to learn, reason, and solve problems—just like we do. It’s behind things like virtual assistants (Siri, Alexa), self-driving cars, and even movie recommendations on Netflix.
AI comes in different levels:
- Narrow AI (Weak AI): This type of AI is built for specific tasks, like recognizing your voice or suggesting a playlist.
- General AI (Strong AI): This is the dream—AI that can think and reason as flexibly as a human. We’re not quite there yet!
A big part of AI is Natural Language Processing (NLP), which helps computers understand and generate human language. NLP is why you can chat with a bot, ask Google a question, or get automatic subtitles on videos.
Some cool things NLP can do:
- Break down sentences (like figuring out where one word ends and another begins).
- Understand meaning (so it knows “bank” can mean both a riverbank and a financial institution).
- Pick out important names and places (like recognizing “Elon Musk” as a person).
- Analyze emotions (like knowing if a tweet is happy, angry, or sarcastic).
This is where Large Language Models (LLMs) come in. These AI-powered models, like ChatGPT,Liama,DeepSeek take NLP to the next level by generating text that sounds natural, answering questions, and even writing articles (like this one!). They’re changing the way we interact with technology, making AI feel more human than ever before.
What Are Large Language Models (LLMs)? 🔠
Think of Large Language Models (LLMs) as AI-powered superbrains that can understand and generate human-like text. They’re trained on massive amounts of data—books, websites, articles, and more—so they can answer questions, write stories, summarize information, and even have conversations that feel natural.
At their core, LLMs use deep learning and a special kind of AI called transformers to predict what words should come next in a sentence. That’s why they can chat with you, complete sentences, or even generate creative ideas!
Some of the most well-known LLMs include GPT (by OpenAI), Google’s PaLM, DeepSeek and Meta’s LiaMA. These models power chatbots, virtual assistants, and a ton of other AI applications that make our lives easier. Whether you’re asking ChatGPT for help with homework or using AI to generate a business email, you’re benefiting from an LLM in action!
Key characteristics of LLMs
So, what makes Large Language Models (LLMs) so special? Why is everyone talking about them? Let’s dive into the key features that set these AI models apart—and why they’re such a big deal.
1. They’re Massive (Like, Really Massive)
When we say “large,” we mean it! LLMs are trained on huge amounts of data—think billions of words from books, articles, websites, and more. This helps them learn the nuances of human language.
They also have tons of parameters (the parts of the model that store what it’s learned). For example, GPT latest model has hundreds of billions of parameters. That’s like giving the model a super-detailed map of how language works.
2. They’re Super Versatile
LLMs are like Swiss Army knives for language tasks. Need a poem? Done. Need a summary of a long article? Easy. Translation, coding help, answering questions—you name it, they can do it.
They’re not limited to one specific job. Instead, they’re general-purpose tools that can adapt to a wide range of tasks with a little fine-tuning.
3. They Understand Context (Most of the Time)
One of the coolest things about LLMs is their ability to understand context. They don’t just look at words in isolation—they consider the whole sentence, paragraph, or even conversation to figure out what you mean.
This is thanks to something called the transformer architecture, which lets the model focus on the most important parts of the text. It’s like having a built-in highlight reel for language.
4. They Can Generate Human-Like Text
Ever chatted with a bot and thought, “Wait, is this a real person?” That’s LLMs at work. They’re really good at generating text that sounds natural and flows well.
Whether it’s writing an essay, crafting an email, or even creating a story, LLMs can produce text that’s surprisingly coherent and creative.
5. They Learn from Us (For Better or Worse)
LLMs are trained on data created by humans, which means they pick up on our patterns, styles, and even our quirks. This is great for mimicking human language, but it also means they can inherit our biases or mistakes.
For example, if the training data has biased language, the model might unintentionally reflect that in its responses. It’s something developers are constantly working to improve.
6. They’re Always Learning (Well, Kind Of)
While LLMs don’t learn in real-time (yet), they can be fine-tuned for specific tasks or industries. For instance, you can train an LLM to be an expert in medical terminology or legal jargon.
This adaptability makes them incredibly useful for specialized fields, not just general-purpose tasks.
7. They’re Power-Hungry
Let’s be real: LLMs need a lot of computational power. Training these models requires massive servers and tons of energy. It’s one of the reasons they’re mostly developed by big tech companies or research labs.
But once they’re trained, using them is relatively efficient—which is why tools like ChatGPT can run on your laptop or phone.
8. They’re Shaping the Future
LLMs aren’t just a tech trend—they’re changing how we interact with machines. From helping us write code to making customer service bots smarter, they’re becoming a part of everyday life.
And as they keep improving, they’re opening up new possibilities for creativity, productivity, and even education.
How Do Large Language Models Work? 🪄
◾The Training Phase: Where the Magic Happens
During the training phase the LLM transitions from complete ignorance all the way to mastering text processing abilities. A massive neural network requires training similar to teaching child literacy while processing massive text data instead of books. Let’s break it down.
1) Feeding the Model with Massive Text Datasets
First things first, the model needs data—lots and lots of data. We’re talking about massive text datasets that include everything from books, websites, research papers, and even social media posts. Imagine dumping the entire Library of Congress into the model’s brain, but way bigger. This data is the foundation of the model’s knowledge.
Why so much data? Because language is incredibly complex. To understand and generate text, the model needs to see as many examples as possible of how humans use language in different contexts. It’s like learning to cook by reading thousands of recipes—eventually, you start to see patterns and understand how ingredients work together.
2) Learning Patterns, Grammar, and Context
The model uses contemporary methods to discover patterns instead of memorizing the text as it did previously. Reading extensively reveals to you the basic structure of sentences and the relationships between words along with sentence grammar rules. Using a much bigger scale the model executes identical operations.
The model discovers connections between “cat” and “dog” as animals together along with understanding “running” involves your legs and “The sky is _” most likely ends with “blue.” The model identifies the same subtle linguistic elements that humans can including use of tone and contextual information and written sarcasm. The vast number of examples exposed to LLMs enables them to create text which impresses human readers because the models grasp human writing and speaking patterns.
3) The Role of Tokens, Embeddings, and Neural Networks
Okay, here’s where things get a bit technical, but I’ll keep it simple. To process all this text, the model breaks it down into smaller pieces called tokens. A token can be a word, part of a word, or even a punctuation mark. For example, the sentence “I love AI!” might be split into tokens like [“I”, “love”, “AI”, “!”].
Once the text is tokenized, the model converts these tokens into embeddings. Embeddings are like numerical representations of words that capture their meaning and relationships. For instance, the embeddings for “king” and “queen” will be close to each other because they’re both royalty, but far from the embedding for “apple.”
These embeddings are then fed into a neural network, which is essentially a giant web of interconnected nodes (think of it like a brain with billions of neurons). The neural network processes the embeddings, learns the relationships between words, and predicts what comes next in a sentence. Over time, it gets really good at this prediction game.
How Does the Model Improve?
During training, the model makes predictions (like guessing the next word in a sentence) and checks how close it was to the actual answer. If it’s wrong, it adjusts its internal parameters to do better next time. This process is repeated millions (or even billions) of times across the entire dataset. It’s like practicing a skill over and over until you get it right.
The End Result: A Language Wizard
The modeling process on supercomputers spans weeks to months which results in a language mastery ability of the model. Through training on supercomputers it takes in patterns grammar and contextual understanding of human language to become capable of writing essays answering questions and translating languages as well as writing code.
During its training process the model learns to recognize linguistic patterns yet without achieving an understanding of language on a human level. The system displays extraordinary abilities at completing text predictions based on information consumption. The model produces occasional errors because of its ability to match sequences it previously learned. Although it requires improvement it does its job incredibly well.
So, to sum it up, training an LLM is like teaching a machine to read and write by exposing it to a mountain of text data. It learns patterns, grammar, and context by breaking text into tokens, converting them into embeddings, and processing them through a neural network. The result? A model that can chat with you, write stories, and even help with your homework.
◾Transformers: The Power Behind LLMs
Transformers are a type of neural network architecture that was introduced in a groundbreaking paper in 2017 called “Attention is All You Need.” (Yes, that’s the actual title, and it’s as bold as it sounds!) Before Transformers, we had other models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks), which were good but had some serious limitations. Transformers came along and said, “Hold my coffee,” and changed everything.
The Secret Sauce: The Attention Mechanism
Transformers include an innovation known as attention mechanism which stands as the core element. Here is an easy to understand definition of this concept.
Reading this sentence the text presents: “The cat sat on the mat because it was tired.” The correct interpretation of this sentence demands identification of the specific thing being referred to by “it”. Is it the cat or the mat? Your brain selects the word “cat” at first because of its logical relation to the surrounding phrases. The attention mechanism inside Transformers allows machines to find the vital elements within text content.
Through the attention mechanism models can determine how significant different sentence words are in relation to other words. Throughout the word processing of “it” the model displays attention to “cat” while ignoring “mat” because “cat” plays a more important role in the context. The transformers acquire their powerful capabilities because they excel at focusing on contextual text.
Why Are Transformers Better Than Older Models?
Transformers contain attributes which make them superior to traditional models RNNs and LSTMs. Here’s the lowdown:
1) Handling Long-Range Dependencies
Each word in a sequence underwent processing through the sequential approach of RNNs until the previous generation of neural network models arrived. The vulnerable memory system of transformers made it difficult to hold onto earlier occurrences from a lengthy text. The RNN model would face difficulties in understanding the relationship between “cat” and “stretched” because they appear distant from each other in the sentence “The cat, which had been sleeping all day, finally woke up and stretched.”
Through the attention mechanism Transformers examine full sentences simultaneously which allows them to connect widely spaced words easily. Their ability to track context runs smoothly even through long texts because of their design.
2) Parallel Processing
The processing sequence of one word at a time in RNNs proved to be slow and inefficient. The processing of an entire sentence by transformers occurs instantly due to their architecture design. Their ability to process all words at once during training leads to faster speed while increasing their capacity to handle large volumes of data.
3) Better at Capturing Nuance
Thankfully the attention mechanism allows Transformers to identify the nuanced relationships that occur between words. Transformers establish that within the sentence “The bank of the river was full of fish” the term “bank” has a geographical meaning rather than financial application. Technological improvements since then have allowed newer models to more easily process subtelities.
4) Versatility
The transformers operate effectively on text data yet researchers have modified this technology to work with images as well as speech inputs and game systems. Transformers operate as a multifunctional AI tool because of their ability to adapt to different functions.
How Do Transformers Work? A Quick Peek Under the Hood
Let’s get a little technical, but I’ll keep it simple. A Transformer model has two main parts:
Encoder: This part takes the input text (like a sentence) and converts it into a series of embeddings (numerical representations) while using the attention mechanism to understand the relationships between words.
Decoder: This part takes the embeddings and generates output text, like a translation or a continuation of the sentence. It also uses attention to focus on the most relevant parts of the input.
In models like GPT, only the decoder is used for text generation, while models like BERT use only the encoder for tasks like understanding text.
Why Transformers Are the Backbone of LLMs
Transformers serve as the key technology that enables LLMs including GPT, DeepSeek to compose essays along with providing answers and creating amusing jokes. Due to their context analysis abilities and parallel text processing with relationship recognition transformers work outstandingly for creating natural human-like textual content.
The emergence of Transformers revolutionized AI models because they brought capabilities similar to modern smartphones beyond what previous flip phones provided. The new generation of transformers functions as advanced smartphones due to their high speed and power capabilities combined with their unprecedented functionality.
◾Fine-Tuning & Reinforcement Learning
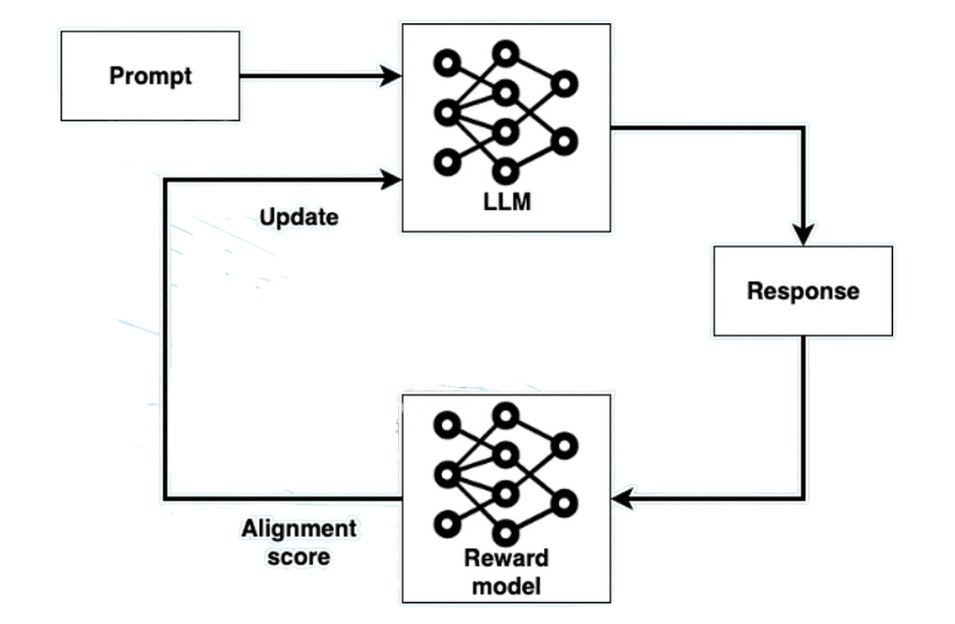
These super-smart LLMs such as ChatGPT and DeepSeek begin their operation as powerful yet rough models. An extensive training process using data from the internet has enabled them to produce human-like texts and respond to questions while also composing verses. The extensive reading habits of these models do not guarantee appropriate or safe responses that match human needs. Fine-tuning provides the entrance for reinforcement learning from human feedback (RLHF) to operate.
Fine-Tuning: The First Step
Think of fine-tuning as the “polishing phase” of an AI model.
When an LLM (Large Language Model) like ChatGPT is first trained, it learns from a huge dataset (books, websites, research papers, etc.). But this raw training data isn’t perfect—it might contain outdated, biased, or even incorrect information.
That’s where fine-tuning comes in. Instead of making the model learn from scratch again, fine-tuning adjusts and refines its knowledge based on specific guidelines and user feedback.
💡 Analogy: Imagine you’re learning to cook. Initially, you watch a lot of cooking videos and read recipe books (raw training). But as you experiment in the kitchen, you make adjustments based on taste tests and expert feedback (fine-tuning).
But fine-tuning alone isn’t enough. Why? Because even with curated data, the model might still generate responses that are off-topic, inappropriate, or just not very useful. That’s where reinforcement learning from human feedback (RLHF) comes into play.
◾Reinforcement Learning from Human Feedback (RLHF)
RLHF is like teaching the model through a feedback loop. Here’s how it works in simple terms:
Human Feedback Collection: Users must interact with the model to provide evaluations regarding its responses. When using ChatGPT you would provide a high score to answers which supply excellent responses. Your rating of the model becomes lower when its response is insufficient or wrong. The obtained feedback leads to the development of reward parameters.
Reward Model Training: The reward model learns to predict how humans would rate different responses. It’s like a little judge that decides whether a response is good or bad based on what humans have said in the past.
Reinforcement Learning: A new fine-tuning process occurs with the LLM but it guides its adjustments using the reward model. The system uses LLM-generated responses which the reward model evaluates before the LLM modifies its output to achieve higher ratings. The model operates according to a system which requires it to receive maximum approval ratings from real-life individuals.
💡Analogy: Imagine training a dog. Your providing treats during successful command responses (positive reinforcement) leads the dog to master its commands better with time.
Why Does RLHF Matter?
Without RLHF, AI models would:
👎 Struggle with accuracy
👎 Be more biased or misleading
👎 Fail to understand human emotions & intent
With RLHF, AI models:
✅ Become more useful & relevant
✅ Learn from real human interactions
✅ Improve over time with continuous feedback
RLHF is a big deal because it bridges the gap between raw computational power and human values. Without it, LLMs might generate text that’s technically correct but not very helpful or even harmful. With RLHF, we can steer these models toward being more ethical, accurate, and user-friendly.
As AI models get smarter, RLHF will play a bigger role in keeping them ethical, accurate, and unbiased.
So next time you chat with an AI like ChatGPT, remember—it’s constantly learning from your interactions! Every thumbs-up 👍 or thumbs-down 👎 helps fine-tune its intelligence.
And thanks to Reinforcement Learning from Human Feedback (RLHF), AI is getting closer to truly understanding us.
Why Do Large Language Models (LLM) Matter? 🧩
Imagine having a super-smart assistant who can write, code, teach, and even help solve some of the world’s biggest problems. That’s what LLMs bring to the table. They’re not just about generating text; they’re about amplifying human potential. Whether you’re a writer, a developer, a teacher, or a scientist, these models are here to make your life easier and more productive. Sounds pretty cool, right?
🌻Let’s dive into some real-world applications where they’re making a huge impact.
🔠Content Generation
Ever chatted with a customer service bot or read a blog post that felt surprisingly human? That’s LLMs at work. They’re powering chatbots, helping marketers write compelling copy, and even drafting entire articles. It’s like having a creative partner who never runs out of ideas. For businesses, this means saving time and money while keeping content fresh and engaging.
🧑💻Code Generation
If you’re a developer, you’ve probably heard of GitHub Copilot. It’s like having a coding buddy who suggests lines of code, fixes bugs, and even explains complex concepts. LLMs are revolutionizing how we write software, making coding faster and more accessible—even for beginners. It’s not about replacing developers; it’s about empowering them to do more.
📖Education & Personalized Learning
Imagine having a personal AI tutor that adapts to your learning style. LLMs power AI-driven education platforms that provide personalized learning experiences, explain complex topics in simple terms, and even generate quizzes or study guides. Whether you’re learning a new language, preparing for exams, or exploring a new field, AI is making education more accessible and engaging.
🤖Customer Support & Virtual Assistants
We’ve all been there—stuck on hold, waiting for a human agent. LLMs are changing that. They’re powering virtual assistants that can handle FAQs, troubleshoot issues, and even upsell products. The best part? They’re available 24/7, so you don’t have to wait for business hours to get help.
🩺Medical Research & Drug Discovery
AI brings transformative medical solutions to healthcare beyond its role in content generation and chatbot technology. Using LLMs enables the evaluation of massive medical research collections along with disease pattern forecasting and drug development assistance. AI platforms speed up treatment advancement and assist medical professionals to deliver data-based decisions.
Challenges & Ethical Concerns of LLMs ⚖️
Alright, let’s talk about the not-so-glamorous side of large language models (LLMs). Sure, they’re amazing, but they come with their fair share of challenges and ethical concerns. It’s like having a super-smart friend who sometimes says the wrong thing or accidentally spills your secrets.
⚠️ AI is amazing, but it’s not perfect. Large Language Models (LLMs) come with their fair share of challenges and ethical concerns that we need to talk about.
🔴 Bias & Misinformation: The learning process of LLMs occurs through the data they receive during training and this leads to predicted outcomes. That data isn’t perfect. Biased training data will usually transmit its biases to the created models. The model has a potential to create unbalanced or discriminatory outputs that may hurt people. The ignorance of LLMs about what is true or false makes them prone to spread misinformation to users because they primarily predict plausible content.
⁉️ Hallucinations: Ever seen AI confidently give a completely wrong answer? That’s called an AI “hallucination.” LLMs sometimes make things up, even if they sound believable. This can be dangerous, especially in fields like healthcare, law, and news reporting.
🔏 Data Privacy: The large training data for LLMs includes comprehensive information which might contain sensitive personal details. The handling of sensitive information by LLMs remains a challenge because improper care during processing may reveal private information and secret data. A situation where an AI system unintentionally reveals personal information of someone would turn into an immediate privacy disaster.
⚖️ AI Regulation & Ethics: Should AI be monitored or controlled? Some argue that AI should have strict regulations to prevent misuse (e.g., deepfakes, AI-generated propaganda). Others believe too many restrictions could slow innovation. Finding the balance is key.
The Future of Large Language Models 🌱
AI is evolving at lightning speed, and Large Language Models (LLMs) are no exception. But what’s coming next? Will AI become even more human-like?
Short answer: Yes, and it’s already happening! Future LLMs will understand context better, show emotions in responses, and even hold deeper, more meaningful conversations. Imagine talking to an AI that truly gets you—whether it’s for customer service, therapy, or just casual chats.
🌍 What’s Next?
🚀 Multi-Modal AI: AI won’t just process text—it will understand images, videos, and sounds together. Think AI that can describe an image, analyze video, and answer questions about it in real-time.
🤖 AI Agents: Instead of just answering questions, AI will act like a personal assistant, handling tasks autonomously—from booking flights to managing emails.
🧠 Better Reasoning & Decision-Making: LLMs will think more critically, making them more reliable for problem-solving, research, and even legal or medical analysis.
LLMs are going to change the game. In the workplace, they’ll take over repetitive tasks, freeing us up to focus on creativity and strategy. But they’ll also create new jobs (like AI trainers or ethicists) and force us to rethink skills and education.
‼️We’re heading toward a world where AI will be more than just a tool—it will be a digital partner. The key is to use it wisely and ethically.
FAQ 💡
What are Large Language Models (LLMs)?
Large Language Models (LLMs) are advanced AI systems trained on vast amounts of text data to understand, generate, and manipulate human language. They power applications like chatbots, content creation, and language translation.
What are the key applications of Large Language Models?
LLMs are used in various fields, including natural language processing (NLP), customer support automation, content generation, code completion, sentiment analysis, and personalized recommendations.
What are the challenges of using Large Language Models?
Challenges include high computational costs, ethical concerns (e.g., bias and misinformation), data privacy issues, and the need for continuous fine-tuning to improve accuracy and relevance.
How do Large Language Models impact businesses?
LLMs help businesses automate tasks, improve customer engagement, and enhance decision-making through data analysis. However, they also require significant investment in infrastructure and expertise.
What is the future of Large Language Models?
The future of LLMs includes advancements in efficiency, reduced bias, better contextual understanding, and integration with other AI technologies like computer vision and robotics.
How do Large Language Models handle bias and ethical concerns?
Addressing bias in LLMs involves using diverse training datasets, implementing fairness algorithms, and regularly auditing models to ensure ethical and unbiased outputs.
What are the limitations of Large Language Models?
Limitations include high energy consumption, difficulty in understanding context in complex scenarios, and the risk of generating inaccurate or harmful content.
How do Large Language Models compare to traditional NLP models?
Unlike traditional NLP models, LLMs are trained on massive datasets and can perform a wide range of tasks without task-specific training, making them more versatile but also more resource-intensive.
